Im vergangenen Beitrag habe ich etwas leichtfertig behauptet, der auffällige Unterschied zwischen den Browserstatistiken sei vermutlich Folge der Tatsache, dass der eine Counter vor allem von Seiten mit technisch versierten Lesern, der andere eher von solchen mit „Durchschnittslesern“ genutzt werde. Prompt gab es Kritik – nicht ganz zu unrecht, wie ich einräumen muss, denn diese Aussage ist pure Spekulation.
Das Wort Browser dürfte übrigens vom englischen Wort für durchstöbern beziehungsweise von sich umsehen kommen. Auch das ist Spekulation, allerdings halte ich andere Übersetzungen wie äsen, grasen oder weiden für sehr wahrscheinlich.
Als Zufall würde ich die Daten nicht bezeichnen. Wenn beispielsweise Spiegel Online schreibt, tagsüber würden die Leser vor allem mit dem Internet Explorer (vom Büro) zugreifen, Abends dagegen mit Firefox (von zuhause), dann ist das vielmehr ein klarers Muster. Wie im vergangenen Beitrag dargestellt, ist es also wichtig, welche Zielgruppen eine Seite lesen.
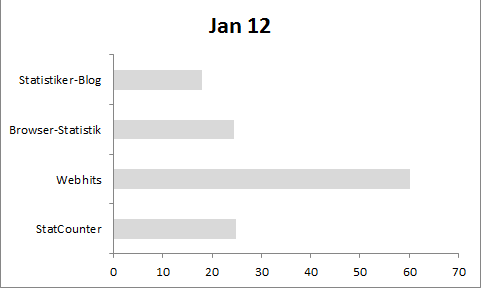
Ein Stück weit gleichen sich diese Effekte allerdings aus, wenn verschiedene Seiten mit einbezogen werden. Mit Ausnahme des Statistiker-Blogs berücksichtigen die in der Grafik dargestellte Quellen alle mehrere Seiten. Unter Statistiker-Blog verbergen sich dagegen die Zugriffe auf meine Seite. Allerdings weichen die Daten von webhits so deutlich ab, dass meine Behauptung mir mittlerweile tatsächlich etwas gewagt vorkommt.
Fazit: Mit Zufall hat das nichts zu tun, aber Aussagen über die Browsernutzung sind nur schwer zu treffen. Dazu müsste man zufällig Seiten auswählen. Anders sieht es mit Trendaussagen aus. Hier gehen die Daten in die gleiche Richtung. Diese lassen sich also durchaus treffen.
Interessant wird es, wenn es um die wirklich großen Seiten geht, die wirklich jeder benutzt: Google, Wikipedia, Amazon, Facebook & Co. Da kommt dann schnell eine doch recht genaue Statistik zusammen:
http://en.wikipedia.org/wiki/Usage_share_of_web_browsers#Wikimedia_.28April_2009_to_present.29